An introduction to chantrics
Theo Bruckbauer
2021-10-08
Source:vignettes/chantrics-vignette.Rmd
chantrics-vignette.Rmdchantrics applies the Chandler-Bate loglikelihood adjustment (Chandler and Bate 2007) implemented in the chandwich package (Northrop and Chandler 2020) to different models frequently used in basic Econometrics applications. adj_loglik() is the central function of chantrics, it is a generic function adjusting the parameter covariance matrix of the models to incorporate clustered data, and can mitigate for model misspecification. The returned object can then be plugged into a range of model analysis functions, which will be described below.
Functionality for singular model objects
Note that not all functionality demonstrated below is available for all types of models.
In order to be able to demonstrate the range of functionality available, this example will be using the misspecified count data regression from Chapter 5.1 in the Object-Oriented Computation of Sandwich Estimators vignette from the sandwich package (Zeileis 2006).
First, data from a negative binomial model is generated, and then a Poisson model is fit, which is clearly misspecified.
set.seed(123)
x <- rnorm(250)
y <- rnbinom(250, mu = exp(1 + x), size = 1)
## Fit the Poisson glm model, which is not correctly specified
fm_pois <- glm(y ~ x + I(x^2), family = poisson)
lmtest::coeftest(fm_pois)
#>
#> z test of coefficients:
#>
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 1.063268 0.041357 25.7094 < 2e-16 ***
#> x 0.996072 0.053534 18.6062 < 2e-16 ***
#> I(x^2) -0.049124 0.023146 -2.1223 0.03381 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## The I(x^2) term is spuriously significant.We can now use the model object fm_pois, and adjust it using adj_loglik(). Use coef() to get a vector of the coefficients, summary() to get an overview over the adjustment, or use lmtest::coeftest() to see the results of \(z\) tests on each of the coefficients.
fm_pois_adj <- adj_loglik(fm_pois)
coef(fm_pois_adj) # class "numeric"
#> (Intercept) x I(x^2)
#> 1.06326821 0.99607219 -0.04912373
summary(fm_pois_adj)
#> MLE SE adj. SE
#> (Intercept) 1.06300 0.04136 0.08378
#> x 0.99610 0.05353 0.10520
#> I(x^2) -0.04912 0.02315 0.03628
lmtest::coeftest(fm_pois_adj)
#>
#> z test of coefficients:
#>
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 1.063268 0.083776 12.6918 <2e-16 ***
#> x 0.996072 0.105217 9.4668 <2e-16 ***
#> I(x^2) -0.049124 0.036284 -1.3539 0.1758
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Confidence intervals of the estimates
The function chandwich::conf_intervals() returns confidence intervals at the level specified in conf (default: 95). To use one of the other specifications of the adjustment from Chandler and Bate (2007), use the type argument. Many other adjustments are available. The classic S3 method confint() is also available.
chandwich::conf_intervals(fm_pois_adj)
#> Waiting for profiling to be done...
#> Model: poisson_glm_lm
#>
#> 95% confidence intervals, adjusted loglikelihod with type = ''vertical''
#>
#> Symmetric:
#> lower upper
#> (Intercept) 0.89907 1.22747
#> x 0.78985 1.20229
#> I(x^2) -0.12024 0.02199
#>
#> Profile likelihood-based:
#> lower upper
#> (Intercept) 0.8954 1.2232
#> x 0.7877 1.1991
#> I(x^2) -0.1198 0.0222
chandwich::conf_intervals(fm_pois_adj, type = "spectral", conf = 99)
#> Waiting for profiling to be done...
#> Model: poisson_glm_lm
#>
#> 99% confidence intervals, adjusted loglikelihod with type = ''spectral''
#>
#> Symmetric:
#> lower upper
#> (Intercept) 0.84748 1.27906
#> x 0.72505 1.26709
#> I(x^2) -0.14258 0.04434
#>
#> Profile likelihood-based:
#> lower upper
#> (Intercept) 0.84491 1.27554
#> x 0.73069 1.27167
#> I(x^2) -0.14497 0.04169
confint(fm_pois_adj)
#> Waiting for profiling to be done...
#> 2.5 % 97.5 %
#> (Intercept) 0.8954172 1.22323347
#> x 0.7876855 1.19906286
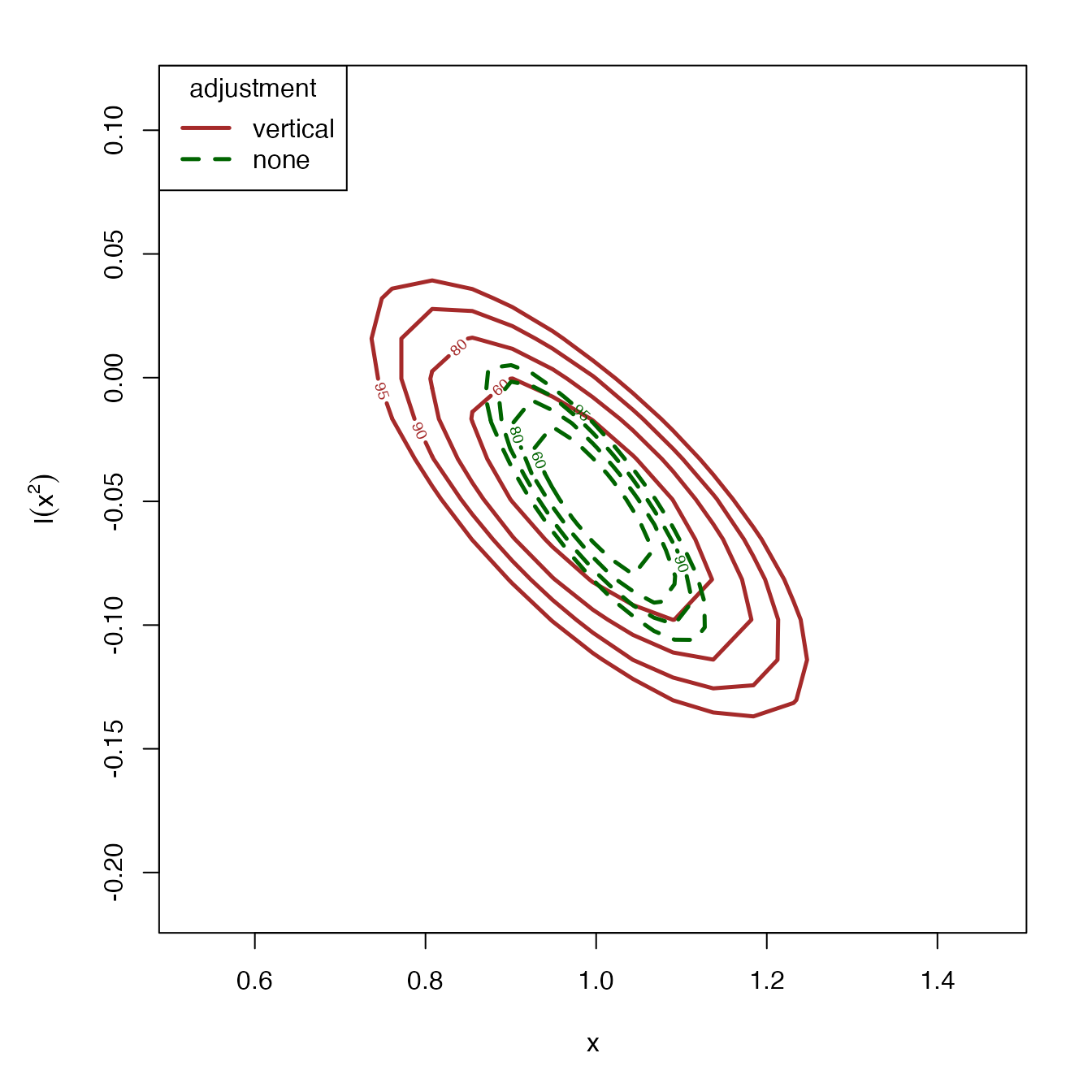
#> I(x^2) -0.1198278 0.02220215We can also plot confidence regions of the estimates for two coefficients using chandwich::conf_region(), where we can specify the parameters using which_pars, the type of specification of the adjustment from Chandler and Bate (2007) using type, and the confidence levels using conf. Other adjustments are available.
fm_pois_adj_vert <-
chandwich::conf_region(fm_pois_adj, which_pars = c("x", "I(x^2)"))
#> Waiting for profiling to be done...
fm_pois_adj_none <-
chandwich::conf_region(fm_pois_adj,
which_pars = c("x", "I(x^2)"),
type = "none"
)
#> Waiting for profiling to be done...
par(mar = c(5.1, 5.1, 2.1, 2.1))
plot(
fm_pois_adj_vert,
fm_pois_adj_none,
conf = c(60, 80, 90, 95),
col = c("brown", "darkgreen"),
lty = c(1, 2),
lwd = 2.5
)
Other diagnostic functions
The methods
-
AIC()for the Akaike Information Criterion, -
df.residual()for the degrees of freedom of the residuals -
fitted()for the fitted values, -
logLik()for the sum of the loglikelihoods andlogLik_vec()for the loglikelihood contributions for each of the observations, and -
vcov()for the variance-covariance matrix, are available.
The performance of the types of adjustments that are shown in Chandler and Bate (2007) can be seen using plot() if there is a single free parameter. Use type to specify the types of adjustment that should show in the plot.
fm_pois_smallest_adj <- update(fm_pois_adj, . ~ 1)
plot(fm_pois_smallest_adj, type = 1:4, col = 1:4, legend_pos = "bottom", lwd = 2.5)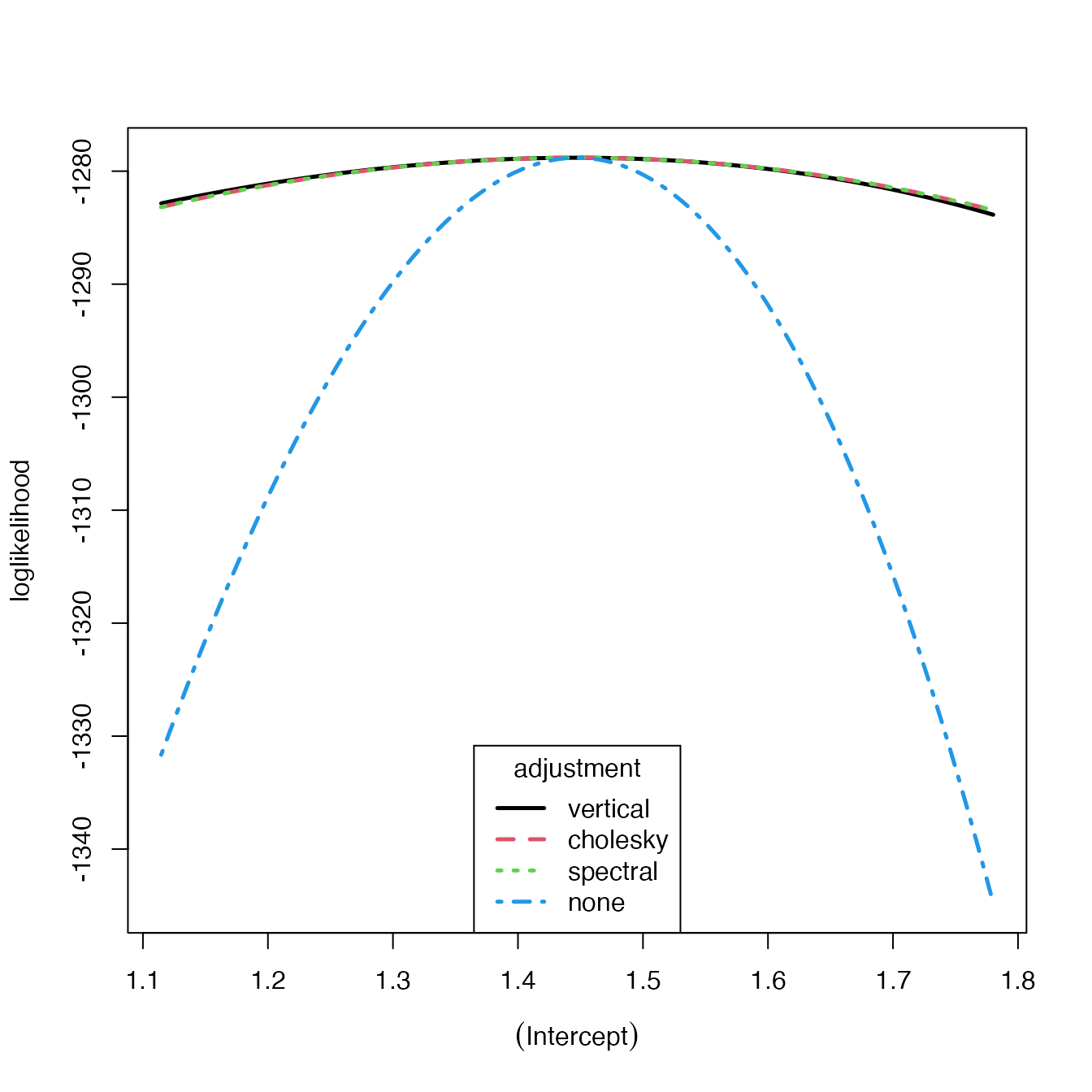
Note that for one free parameter, the Cholesky and the spectral adjustments are identical, and the vertical adjustment only deviates slightly at the edges of the plot.
Functionality for multiple model objects
In order to have a wider range of coefficients to do model comparisons on, we will follow a Probit regression example in Kleiber and Zeileis (2008, 124) using the SwissLabor dataset from the AER package (Kleiber and Zeileis 2020).
data("SwissLabor", package = "AER")
swiss_probit <-
glm(participation ~ . + I(age^2),
data = SwissLabor,
family = binomial(link = "probit")
)
swiss_probit_adj <- adj_loglik(swiss_probit)
lmtest::coeftest(swiss_probit_adj)
#>
#> z test of coefficients:
#>
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 3.749091 1.327072 2.8251 0.004727 **
#> income -0.666941 0.127292 -5.2395 1.611e-07 ***
#> age 2.075297 0.398580 5.2067 1.922e-07 ***
#> education 0.019196 0.017935 1.0703 0.284479
#> youngkids -0.714487 0.106095 -6.7344 1.646e-11 ***
#> oldkids -0.146984 0.051609 -2.8480 0.004399 **
#> foreignyes 0.714373 0.122437 5.8346 5.391e-09 ***
#> I(age^2) -0.294344 0.049527 -5.9430 2.798e-09 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Creating nested models
The update() function is also available for chantrics objects, it automatically re-estimates the updated model, and adjusts the loglikelihood.
Compare nested models
Nested models can be compared with anova() using an adjusted likelihood ratio test as outlined in Section 3.5 in Chandler and Bate (2007). The type of adjustment can again be set using type. anova() sorts the models by the number of free variables as returned by attr(model, "p_current"), where model is the chantrics model object.
anova(swiss_probit_adj, swiss_probit_small_adj, swiss_probit_smaller_adj)
#> Analysis of Adjusted Deviance Table
#>
#> Model 1: participation ~ income + age + education + youngkids + oldkids +
#> foreign + I(age^2)
#> Model 2: participation ~ income + age + youngkids + oldkids + foreign
#> Model 3: participation ~ income + age + foreign
#>
#> Resid.df df ALRTS Pr(>ALRTS)
#> 1 864
#> 2 866 2 37.359 7.721e-09 ***
#> 3 868 2 53.619 2.274e-12 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1By passing in a singular model, we can also use anova() to generate a sequential analysis of deviance table, where each of the covariates is sequentially removed from the model.
anova(swiss_probit_adj)
#> Analysis of Adjusted Deviance Table
#>
#> Model 1: participation ~ income + age + education + youngkids + oldkids +
#> foreign + I(age^2)
#> Model 2: participation ~ income + age + education + youngkids + oldkids +
#> foreign
#> Model 3: participation ~ income + age + education + youngkids + oldkids
#> Model 4: participation ~ income + age + education + youngkids
#> Model 5: participation ~ income + age + education
#> Model 6: participation ~ income + age
#> Model 7: participation ~ income
#> Model 8: participation ~ 1
#>
#> Resid.df df ALRTS Pr(>ALRTS)
#> full model 864
#> I(age^2) 865 1 36.891 1.249e-09 ***
#> foreign 866 1 45.540 1.496e-11 ***
#> oldkids 867 1 0.027 0.870406
#> youngkids 868 1 43.763 3.707e-11 ***
#> education 869 1 3.531 0.060230 .
#> age 870 1 7.661 0.005644 **
#> income 871 1 27.866 1.300e-07 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Another way of performing an adjusted likelihood ratio test is by using alrtest(), which is inspired and similar in usage to lmtest::waldtest() and lmtest::lrtest(), where a model, and an indicator of the variables that should be restricted/removed. These indicators can be character strings of the names of the covariates, integers corresponding to the position of a covariate, formula objects, or nested model objects, allowing a flexible and easy specification of nested models.
alrtest(swiss_probit_adj, 3, "oldkids")
#> Adjusted likelihood ratio test
#>
#> Model 1: participation ~ income + age + education + youngkids + oldkids +
#> foreign + I(age^2)
#> Model 2: participation ~ income + age + youngkids + oldkids + foreign +
#> I(age^2)
#> Model 3: participation ~ income + age + youngkids + foreign + I(age^2)
#>
#> Resid.df df ALRTS Pr(>ALRTS)
#> 1 864
#> 2 865 1 1.1556 0.282373
#> 3 866 1 8.8500 0.002931 **
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
alrtest(swiss_probit_adj, . ~ . - youngkids - foreign, . ~ . - education)
#> Adjusted likelihood ratio test
#>
#> Model 1: participation ~ income + age + education + youngkids + oldkids +
#> foreign + I(age^2)
#> Model 2: participation ~ income + age + education + oldkids + I(age^2)
#> Model 3: participation ~ income + age + oldkids + I(age^2)
#>
#> Resid.df df ALRTS Pr(>ALRTS)
#> 1 864
#> 2 866 2 84.759 <2e-16 ***
#> 3 867 1 1.653 0.1985
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
alrtest(swiss_probit_adj, swiss_probit_small_adj)
#> Adjusted likelihood ratio test
#>
#> Model 1: participation ~ income + age + education + youngkids + oldkids +
#> foreign + I(age^2)
#> Model 2: participation ~ income + age + youngkids + oldkids + foreign
#>
#> Resid.df df ALRTS Pr(>ALRTS)
#> 1 864
#> 2 866 2 37.359 7.721e-09 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Supported models
glm models
In a generalised linear model (glm), the user can choose between a range of distributions of a response \(y\), and can allow for non-linear relations between the mean outcome for a certain combination of covariates \(x\), \(\operatorname{E}(y_i\mid x_i)=\mu_i\), and the linear predictor, \(\eta_i=x_i^T\beta\), which is the link function \(g(\mu_i)=\eta_i\). The link function is required to be monotonic. (For a quick introduction, see Kleiber and Zeileis (2008, Ch. 5.1), for a more complete coverage of the topic, see, for example, Davison (2003, Ch. 10.3))
Within the array of glm families presented below, any link function should work.
poisson family
The Poisson family of models are commonly used specifications for count models. The specification of this form of a GLM is (for the canonical log-link of the Poisson specification),
\[\begin{equation*} \operatorname{E}(y_i\mid x_i)=\mu_i=\exp(x_i^T\beta). \end{equation*}\]
In this example, I will reuse the example of the misspecified count data regression from Chapter 5.1 in the Object-Oriented Computation of Sandwich Estimators vignette from the sandwich package (Zeileis 2006). More on the Poisson specification in glms can be found in Cameron and Trivedi (2013, Ch. 3.2.4) or Davison (2003, Example 10.10). More on the implementation in R is located in Zeileis, Kleiber, and Jackman (2008, Ch. 2.1), and in Kleiber and Zeileis (2008, Ch. 5.3).
summary(fm_pois) # fm_pois is the fitted poisson model from above.
#>
#> Call:
#> glm(formula = y ~ x + I(x^2), family = poisson)
#>
#> Deviance Residuals:
#> Min 1Q Median 3Q Max
#> -5.6471 -1.6122 -0.6344 0.7245 7.1645
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 1.06327 0.04136 25.709 <2e-16 ***
#> x 0.99607 0.05353 18.606 <2e-16 ***
#> I(x^2) -0.04912 0.02315 -2.122 0.0338 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> (Dispersion parameter for poisson family taken to be 1)
#>
#> Null deviance: 1998.1 on 249 degrees of freedom
#> Residual deviance: 1069.7 on 247 degrees of freedom
#> AIC: 1635.2
#>
#> Number of Fisher Scoring iterations: 5
fm_pois_adj <- adj_loglik(fm_pois)
summary(fm_pois_adj)
#> MLE SE adj. SE
#> (Intercept) 1.06300 0.04136 0.08378
#> x 0.99610 0.05353 0.10520
#> I(x^2) -0.04912 0.02315 0.03628
binomial family
The binomial family of models is widely used for binary choice modelling of probabilities of choosing a certain option given a set of properties. As \(\operatorname{E}(y_i\mid x_i)=1\cdot P(y_i=1\mid x_i)+0\cdot P(y_i=0\mid x_i)=P(y_i=1\mid x_i)\), the point estimation of the model is the probability of \(y_i\) being equal to 1. It is specified using the GLM framework described above, with \[\begin{equation*}
\operatorname{E}(y_i\mid x_i)=P(y_i=1)=p_i=F(x_i^T\beta),
\end{equation*}\] where \(F\) is a valid cdf of the error terms in the model, or, equally, the link function. Most commonly, these are chosen to be either the standard normal cdf in the Probit case, family = binomial(link = "probit"), or the logistic cdf in the logit case, family = binomial(link = "logit").
This example will use the SwissLabor example in Kleiber and Zeileis (2008, pg. 124)
data("SwissLabor", package = "AER")
## Fitting a Probit model
swiss_probit <-
glm(participation ~ . + I(age^2),
data = SwissLabor,
family = binomial(link = "probit")
)
swiss_probit_adj <- adj_loglik(swiss_probit)
summary(swiss_probit_adj)
#> MLE SE adj. SE
#> (Intercept) 3.7490 1.40700 1.32700
#> income -0.6669 0.13200 0.12730
#> age 2.0750 0.40540 0.39860
#> education 0.0192 0.01793 0.01793
#> youngkids -0.7145 0.10040 0.10610
#> oldkids -0.1470 0.05089 0.05161
#> foreignyes 0.7144 0.12130 0.12240
#> I(age^2) -0.2943 0.04995 0.04953
## Fitting a Logit model
swiss_logit <-
glm(formula(swiss_probit),
data = SwissLabor,
family = binomial(link = "logit")
)
swiss_logit_adj <- adj_loglik(swiss_logit)
summary(swiss_logit_adj)
#> MLE SE adj. SE
#> (Intercept) 6.19600 2.38300 2.29300
#> income -1.10400 0.22570 0.22140
#> age 3.43700 0.68790 0.67240
#> education 0.03266 0.02999 0.02996
#> youngkids -1.18600 0.17200 0.18180
#> oldkids -0.24090 0.08446 0.08584
#> foreignyes 1.16800 0.20380 0.20570
#> I(age^2) -0.48760 0.08519 0.08384Note that other specifications of the link function are possible, the code is agnostic towards the link function.
gaussian family
The GLM framework encompasses the estimation of a standard linear regression using maximum likelihood estimators, therefore we can use the adjustment to account for clustering/misspecifications in the regression. We can use the classic assumption of normally distributed error terms to specify the distribution of \(y\). The link is simply the identity function. (Kleiber and Zeileis 2008, pg. 123)
To demonstrate the functionality, I will employ the linear regression example in Kleiber and Zeileis (2008, pg. 66), using the cross-sectional CPS1988 data.
data("CPS1988", package = "AER")
cps_glm <-
glm(
log(wage) ~ experience + I(experience^2) + education + ethnicity,
data = CPS1988,
family = gaussian()
)
summary(cps_glm)
#>
#> Call:
#> glm(formula = log(wage) ~ experience + I(experience^2) + education +
#> ethnicity, family = gaussian(), data = CPS1988)
#>
#> Deviance Residuals:
#> Min 1Q Median 3Q Max
#> -2.9428 -0.3162 0.0580 0.3756 4.3830
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 4.321e+00 1.917e-02 225.38 <2e-16 ***
#> experience 7.747e-02 8.800e-04 88.03 <2e-16 ***
#> I(experience^2) -1.316e-03 1.899e-05 -69.31 <2e-16 ***
#> education 8.567e-02 1.272e-03 67.34 <2e-16 ***
#> ethnicityafam -2.434e-01 1.292e-02 -18.84 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> (Dispersion parameter for gaussian family taken to be 0.3409812)
#>
#> Null deviance: 14428.3 on 28154 degrees of freedom
#> Residual deviance: 9598.6 on 28150 degrees of freedom
#> AIC: 49615
#>
#> Number of Fisher Scoring iterations: 2
cps_glm_adj <- adj_loglik(cps_glm)
summary(cps_glm_adj)
#> MLE SE adj. SE
#> (Intercept) 4.321000 1.917e-02 2.061e-02
#> experience 0.077470 8.800e-04 1.018e-03
#> I(experience^2) -0.001316 1.899e-05 2.348e-05
#> education 0.085670 1.272e-03 1.375e-03
#> ethnicityafam -0.243400 1.292e-02 1.311e-02
#> attr(,"dispersion")
#> [1] 0.3409933
#>
#> (Dispersion parameter taken to be 0.341)
MASS::negative.binomial family and MASS::glm.nb()
Another commonly used model for count data is the negative binomial model. It overcomes two issues of the Poisson model, that the expectation and the variance are assumed to be equal, and that in most datasets, the number of zeros is underestimated by Poisson family models.
The method of estimation of the negative binomial model depends on whether the dispersion parameter \(\theta\) of the pmf, \[\begin{equation*}
f(y;\mu,\theta)=\frac{\Gamma(\theta+y)}{\Gamma(\theta)y!}\frac{\mu^y\theta^\theta}{(\mu+\theta)^{y+\theta}}
\end{equation*}\] is known. In most cases, it is not known, and the specialised function MASS::glm.nb() can be used, which estimates the negative binomial model and the \(\theta\) parameter separately. If \(\theta\) is known, the MASS package (Venables and Ripley 2002) provides the MASS::negative.binomial() family function for glm().
A quick introduction can be found in Kleiber and Zeileis (2008, pg. 135f.) and in Zeileis, Kleiber, and Jackman (2008, pg. 5), and a more general treatment with estimation using direct ML estimation in Cameron and Trivedi (2013, Ch. 3.3).
Note that adj_loglik() re-estimates the theta parameter of a glm.nb model.
To demonstrate the negative binomial model functions, we will use the negative binomial data generated above, which we have falsely fitted to a Poisson model.
fm_negbin_theta <- MASS::glm.nb(y ~ x)
summary(fm_negbin_theta)
#>
#> Call:
#> MASS::glm.nb(formula = y ~ x, init.theta = 1.07845966, link = log)
#>
#> Deviance Residuals:
#> Min 1Q Median 3Q Max
#> -2.3259 -1.1607 -0.3757 0.3033 2.6729
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 1.02881 0.07514 13.69 <2e-16 ***
#> x 0.95909 0.07913 12.12 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> (Dispersion parameter for Negative Binomial(1.0785) family taken to be 1)
#>
#> Null deviance: 442.32 on 249 degrees of freedom
#> Residual deviance: 267.02 on 248 degrees of freedom
#> AIC: 1118.7
#>
#> Number of Fisher Scoring iterations: 1
#>
#>
#> Theta: 1.078
#> Std. Err.: 0.143
#>
#> 2 x log-likelihood: -1112.662
fm_negbin_theta_adj <- adj_loglik(fm_negbin_theta)
summary(fm_negbin_theta_adj)
#> MLE SE adj. SE
#> (Intercept) 1.0290 0.07514 0.07683
#> x 0.9591 0.07913 0.06890
#> attr(,"theta")
#> [1] 1.07846
#> attr(,"theta")attr(,"SE")
#> [1] 0.1432373
#>
#> (Theta: 1.078, SE: 0.1432)Clustering
To specify clusters, use the cluster argument in adj_loglik() to specify a vector or factor which indicates the cluster that the corresponding observation belongs to. Without specifying a cluster, adj_loglik() assumes that each observation forms its own cluster.
References
Cameron, Adrian Colin, and Pravin K. Trivedi. 2013. Regression Analysis of Count Data. Second edition. Econometric Society Monographs (53). Cambridge University Press. https://doi.org/10.1017/CBO9781139013567.
Chandler, Richard E., and Steven Bate. 2007. “Inference for Clustered Data Using the Independence Loglikelihood.” Biometrika 94 (1): 167–83. https://doi.org/doi:10.1093/biomet/asm015.
Davison, A. C. 2003. Statistical Models. Cambridge Series on Statistical and Probabilistic Mathematics 11. Cambridge University Press, Cambridge.
Kleiber, Christian, and Achim Zeileis. 2008. Applied Econometrics with R. Edited by Robert Gentleman, Kurt Hornik, and Giovanni Parmigiani. Use R! New York: Springer-Verlag.
———. 2020. Package AER: Applied Econometrics with R. 1.2-9th ed. https://cran.r-project.org/package=AER.
Northrop, Paul J., and Richard E. Chandler. 2020. Chandwich: Chandler-Bate Sandwich Loglikelihood Adjustment. https://CRAN.R-project.org/package=chandwich.
Venables, W. N., and B. D. Ripley. 2002. Modern Applied Statistics with S. Fourth. New York: Springer-Verlag, New York. http://www.stats.ox.ac.uk/pub/MASS4/.
Zeileis, Achim. 2006. “Object-Oriented Computation of Sandwich Estimators.” Journal of Statistical Software, Articles 16 (9): 1–16. https://doi.org/10.18637/jss.v016.i09.
Zeileis, Achim, Christian Kleiber, and Simon Jackman. 2008. “Regression Models for Count Data in R.” Journal of Statistical Software, Articles 27 (8): 1–25. https://doi.org/10.18637/jss.v027.i08.